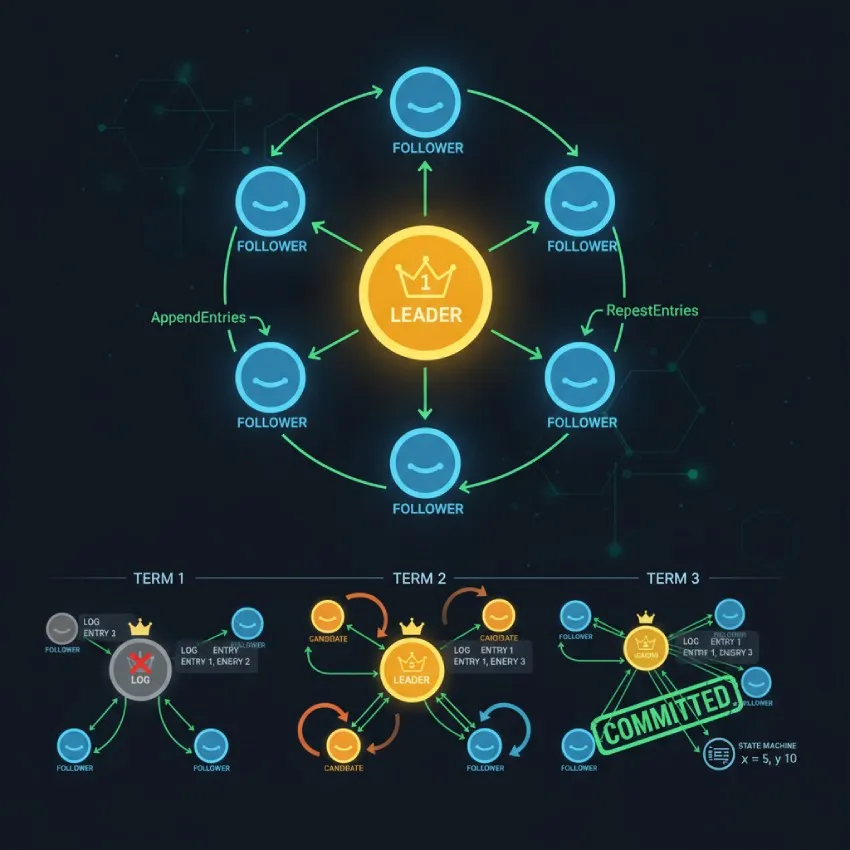
در سیستمهای توزیعشده، جایی که چندین کامپیوتر (گره) با یکدیگر همکاری میکنند تا یک وظیفه واحد را انجام دهند، یکی از بزرگترین چالشها رسیدن به توافق یا اجماع است. چگونه میتوان اطمینان حاصل کرد که تمام گرهها در مورد وضعیت سیستم، دیدگاه یکسانی دارند، حتی زمانی که برخی از گرهها از کار میافتند یا پیامها در شبکه گم میشوند؟ اینجا است که الگوریتمهای اجماع وارد میدان میشوند و الگوریتم رافت (Raft Consensus Algorithm) به عنوان یکی از قابل فهمترین و پراستفادهترین الگوریتمها در این حوزه شناخته میشود.
رافت در سال ۲۰۱۳ توسط دیگو آتگار و جان اوسترهاوت در دانشگاه استنفورد به عنوان جایگزینی سادهتر برای الگوریتم پیچیدهی Paxos معرفی شد. هدف اصلی طراحان رافت، ساخت یک الگوریتم اجماع بود که از نظر عملکردی معادل Paxos باشد، اما درک و پیادهسازی آن به مراتب آسانتر باشد. این سادگی باعث شده است که رافت به سرعت در بسیاری از پروژههای بزرگ نرمافزاری مانند etcd (پایگاه داده کلید-مقدار در Kubernetes)، Consul (ابزار شبکهبندی و سرویس) و CockroachDB (پایگاه داده توزیعشده SQL) به کار گرفته شود.
این مقاله به طور عمیق به بررسی الگوریتم رافت میپردازد. ما ابتدا با تحلیل هدف کاربر از جستجوی این موضوع شروع میکنیم، سپس به اصول بنیادی و نحوه کارکرد آن، از جمله فرآیند انتخاب رهبر (Leader Election) و همانندسازی لاگ (Log Replication) میپردازیم و در نهایت کاربردها و مزایای آن را تشریح خواهیم کرد.
چرا به الگوریتم اجماع نیاز داریم؟ درک مشکل اصلی
قبل از اینکه به جزئیات رافت بپردازیم، باید درک کنیم که چرا اصلاً به چنین الگوریتمی نیاز داریم. تصور کنید یک پایگاه داده توزیعشده دارید که روی سه سرور مختلف اجرا میشود. وقتی یک کاربر داده جدیدی را ثبت میکند، این داده باید روی هر سه سرور نوشته شود تا سیستم سازگار (Consistent) باقی بماند. اما چه اتفاقی میافتد اگر:
-
یکی از سرورها به طور موقت از دسترس خارج شود؟
-
پیام ثبت داده به یکی از سرورها نرسد؟
-
دو کاربر به طور همزمان سعی کنند دادههای متناقضی را در یک مکان ثبت کنند؟
در چنین شرایطی، سیستم ممکن است به حالتی برسد که هر سرور نسخه متفاوتی از دادهها را داشته باشد. این وضعیت که به آن "مغز دوپاره" (Split-Brain) نیز گفته میشود، یک فاجعه برای هر سیستم توزیعشده است. الگوریتمهای اجماع مانند رافت برای جلوگیری از بروز چنین مشکلاتی طراحی شدهاند. آنها تضمین میکنند که تمام گرههای سالم در سیستم، در نهایت بر سر یک ترتیب یکسان از عملیات (که در یک لاگ ثبت میشود) به توافق میرسند و وضعیت سیستم را به صورت هماهنگ بهروزرسانی میکنند. این فرآیند تحملپذیری خطا (Fault Tolerance) را ممکن میسازد.
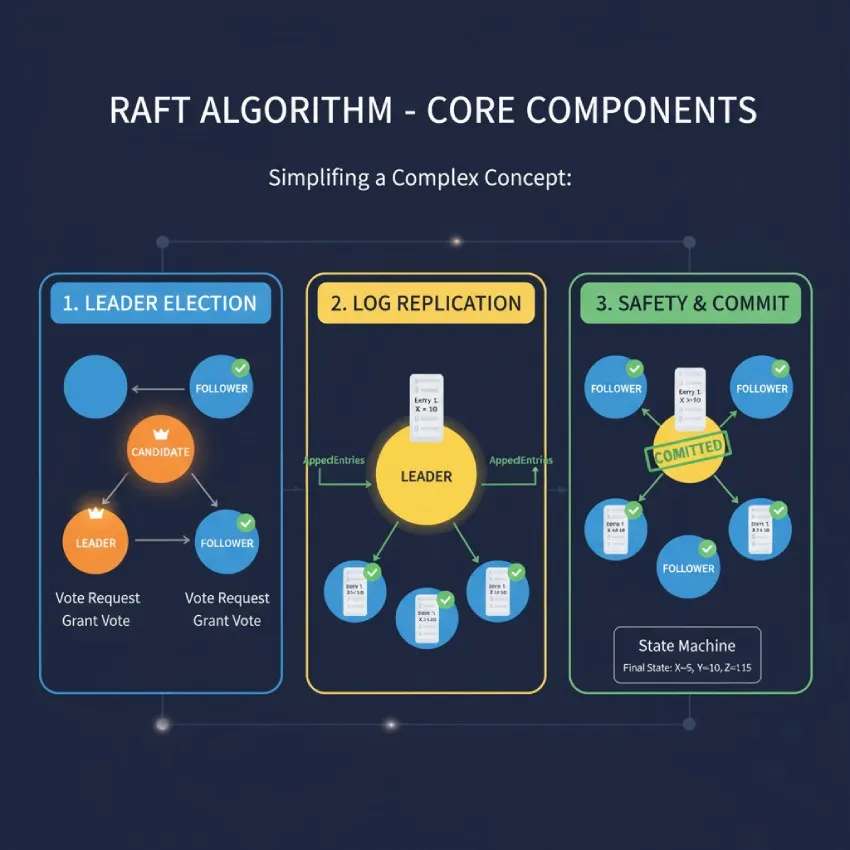
اجزای اصلی الگوریتم رافت: سادهسازی یک مفهوم پیچیده
رافت برای دستیابی به هدف خود، یعنی سادگی و قابل فهم بودن، مسئله اجماع را به سه زیرمسئله مستقل تقسیم میکند:
-
انتخاب رهبر (Leader Election): در هر زمان، فقط یک گره میتواند به عنوان رهبر عمل کند. رهبر مسئولیت تمام تعاملات با کلاینتها و هماهنگی با سایر گرهها را بر عهده دارد.
-
همانندسازی لاگ (Log Replication): رهبر دستورات دریافتی از کلاینتها را به صورت ورودیهایی در لاگ خود ثبت میکند و سپس تلاش میکند تا این لاگ را روی سایر گرهها (که دنبالهرو یا Follower نامیده میشوند) کپی کند تا همه به یک دیدگاه مشترک برسند.
-
ایمنی (Safety): رافت مجموعهای از قوانین را اعمال میکند تا تضمین کند که اگر یک ورودی در لاگ، "متعهد" (Committed) شد، یعنی در اکثر گرهها ثبت شد، در تمام دورههای رهبری آینده نیز باقی خواهد ماند و سیستم هرگز به حالت ناسازگار باز نخواهد گشت.
نقشها و حالتهای مختلف گرهها در رافت
در هر لحظه، هر گره در سیستم رافت در یکی از سه حالت زیر قرار دارد:
-
رهبر (Leader): تنها یک رهبر در یک خوشه (Cluster) وجود دارد. رهبر تمام درخواستهای کلاینت را مدیریت میکند و مسئول همانندسازی لاگ بین گرهها است. او به طور مداوم پیامهای ضربان قلب (Heartbeat) را برای دنبالهروها ارسال میکند تا حضور خود را اعلام کرده و از شروع یک انتخابات جدید جلوگیری کند.
-
دنبالهرو (Follower): تمام گرهها در ابتدا در حالت دنبالهرو هستند. آنها کاملاً منفعل عمل میکنند؛ به درخواستهای رهبر و کاندیداها پاسخ میدهند و هیچ درخواستی را خودشان آغاز نمیکنند. اگر یک دنبالهرو در یک بازه زمانی مشخص (Election Timeout) پیام ضربان قلب از رهبر دریافت نکند، به حالت کاندیدا تغییر وضعیت میدهد.
-
کاندیدا (Candidate): گرهی که میخواهد رهبر شود. وقتی یک دنبالهرو به حالت کاندیدا در میآید، یک انتخابات جدید را آغاز میکند. او برای خودش رأی میدهد و از تمام گرههای دیگر درخواست رأی میکند.
این تقسیمبندی واضح نقشها، یکی از دلایل اصلی سادگی رافت در مقایسه با الگوریتمهای دیگر است.
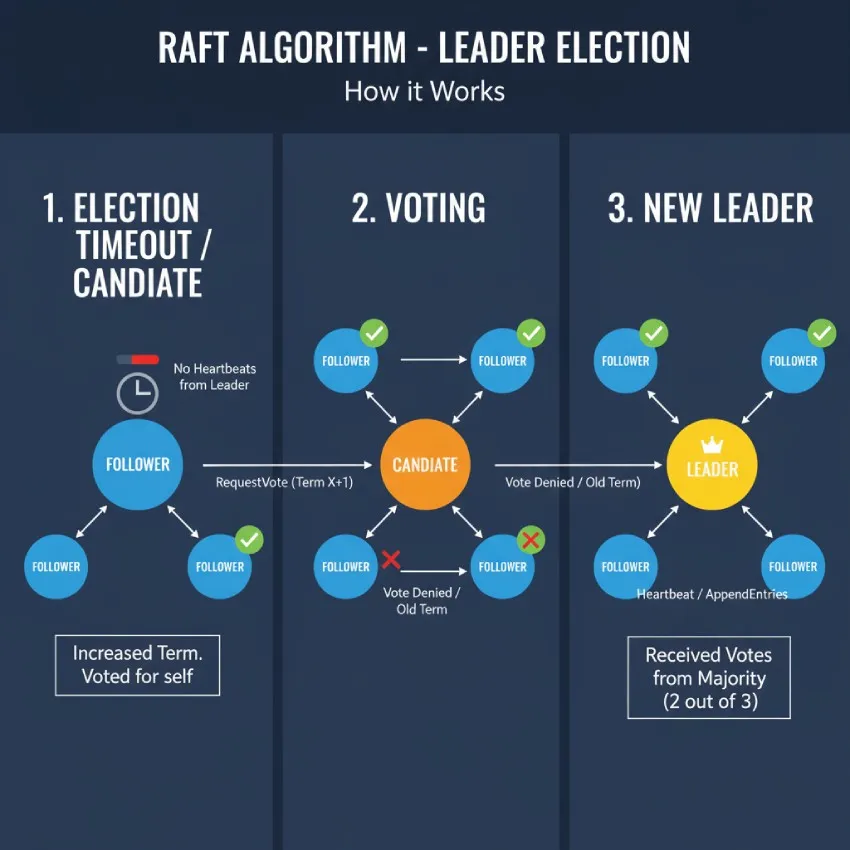
فرآیند انتخاب رهبر (Leader Election) چگونه کار میکند؟
قلب تپنده رافت، فرآیند انتخاب رهبر است. این فرآیند تضمین میکند که حتی در صورت از کار افتادن رهبر فعلی، سیستم به سرعت یک رهبر جدید انتخاب کرده و به کار خود ادامه میدهد.
دورههای زمانی (Terms) در رافت
رافت زمان را به دورههایی با طول متغیر تقسیم میکند که به آنها Term گفته میشود. هر دوره با یک عدد صحیح مثبت و منحصربهفرد مشخص میشود. هر دوره با یک انتخابات آغاز میشود که در آن یک یا چند کاندیدا برای کسب مقام رهبری رقابت میکنند.
-
اگر یک کاندیدا موفق به کسب اکثریت آرا شود، برای باقیمانده آن دوره به عنوان رهبر فعالیت میکند.
-
اگر آرا تقسیم شود و هیچ کاندیدایی اکثریت را به دست نیاورد، آن دوره بدون رهبر به پایان میرسد و یک دوره جدید با یک انتخابات جدید بلافاصله آغاز میشود.
این دورههای زمانی به عنوان یک ساعت منطقی (Logical Clock) در رافت عمل میکنند و به گرهها اجازه میدهند تا اطلاعات قدیمی و منسوخ را شناسایی کنند. برای مثال، اگر گرهی پیامی با شماره دوره بالاتر از دوره فعلی خود دریافت کند، متوجه میشود که اطلاعاتش قدیمی است و بلافاصله دوره خود را بهروزرسانی کرده و به حالت دنبالهرو بازمیگردد.
مراحل یک انتخابات معمولی
-
پایان زمان انتظار (Timeout): یک گره دنبالهرو در حال انتظار پیام ضربان قلب از رهبر است. این زمان انتظار (Election Timeout) معمولاً به صورت تصادفی در یک بازه مشخص (مثلاً ۱۵۰ تا ۳۰۰ میلیثانیه) انتخاب میشود تا از تقسیم آرا و انتخاباتهای ناموفق مکرر جلوگیری شود.
-
شروع انتخابات: اگر زمان انتظار به پایان برسد و دنبالهرو پیامی دریافت نکرده باشد، فرض میکند که رهبر از کار افتاده است. در نتیجه:
-
شماره دوره فعلی خود را یک واحد افزایش میدهد.
-
به حالت کاندیدا تغییر وضعیت میدهد.
-
به خودش رأی میدهد.
-
یک پیام RequestVote به تمام گرههای دیگر در خوشه ارسال میکند و از آنها میخواهد که به او رأی دهند.
-
-
رأیگیری: سایر گرهها پس از دریافت پیام RequestVote، تنها در صورتی به کاندیدا رأی میدهند که:
-
در این دوره هنوز به کاندیدای دیگری رأی نداده باشند.
-
لاگ کاندیدا حداقل به اندازه لاگ خودشان "بهروز" (Up-to-date) باشد. (این شرط ایمنی را تضمین میکند)
-
-
نتیجه انتخابات: کاندیدا منتظر پاسخ گرهها میماند. سه نتیجه ممکن است:
-
پیروزی: اگر کاندیدا رأی اکثریت گرهها را به دست آورد، به عنوان رهبر جدید انتخاب میشود. او بلافاصله پیامهای ضربان قلب را برای همه گرهها ارسال میکند تا رهبری خود را اعلام و از انتخابات جدید جلوگیری کند.
-
شکست (رهبر دیگر): اگر در حین انتظار، پیامی از یک گره دیگر دریافت کند که ادعای رهبری در همین دوره یا دوره جدیدتر را دارد، کاندیدا ادعای او را میپذیرد و به حالت دنبالهرو بازمیگردد.
-
شکست (تقسیم آرا): اگر زمان بگذرد و هیچ کاندیدایی اکثریت آرا را کسب نکند، دوره فعلی به پایان میرسد. کاندیدا زمان انتظار خود را دوباره تنظیم کرده و پس از اتمام آن، یک انتخابات جدید را در یک دوره جدید آغاز میکند.
-
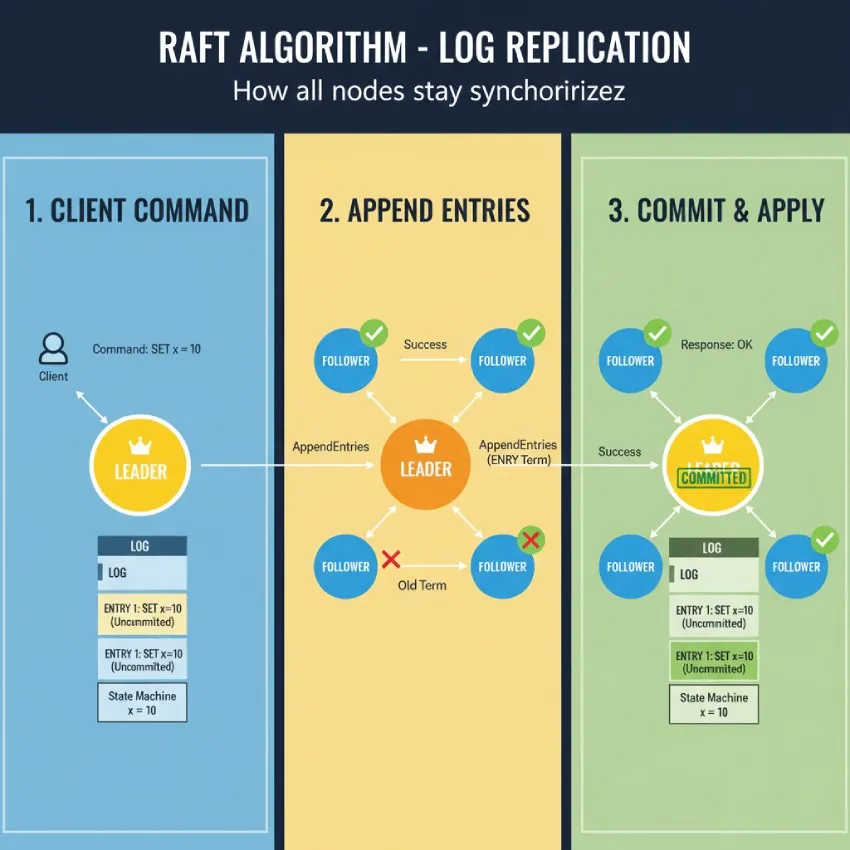
همانندسازی لاگ (Log Replication): چگونه همه گرهها همگام میمانند؟
پس از انتخاب رهبر، سیستم باید به کار اصلی خود یعنی پردازش دستورات کلاینت بپردازد. این کار از طریق فرآیندی به نام همانندسازی لاگ انجام میشود.
هدف این است که یک ماشین حالت همانندسازیشده (Replicated State Machine) ایجاد شود. به عبارت سادهتر، هر گره یک کپی از یک لاگ (لیستی از دستورات به ترتیب) را نگهداری میکند. رهبر مسئولیت دارد که لاگ خود را بر روی لاگ دنبالهروها کپی کند تا در نهایت لاگ تمام گرهها یکسان شود.
مراحل همانندسازی یک دستور جدید
-
دریافت دستور از کلاینت: کلاینت یک دستور (مثلاً
SET x = 5) را به رهبر ارسال میکند. -
افزودن به لاگ رهبر: رهبر دستور را به عنوان یک ورودی جدید به انتهای لاگ خود اضافه میکند. این ورودی در این مرحله هنوز متعهد نشده (Uncommitted) است.
-
ارسال به دنبالهروها: رهبر این ورودی جدید را از طریق پیامهای AppendEntries به تمام دنبالهروها ارسال میکند.
-
پاسخ دنبالهروها: هر دنبالهرو پس از دریافت پیام:
-
بررسیهای ایمنی را انجام میدهد.
-
ورودی جدید را به لاگ خود اضافه میکند.
-
یک پیام موفقیتآمیز بودن عملیات را به رهبر بازمیگرداند.
-
-
تعهد (Commit) کردن ورودی: زمانی که رهبر تأییدیه را از اکثریت گرهها دریافت کند، ورودی را متعهد (Committed) میکند. این بدان معناست که این ورودی به طور دائمی در لاگ ثبت شده و ایمن است.
-
اعمال به ماشین حالت: رهبر دستور موجود در ورودی متعهد شده را بر روی ماشین حالت خود اجرا میکند (مثلاً مقدار متغیر
xرا به5تغییر میدهد). -
اطلاعرسانی به دنبالهروها و کلاینت: در پیامهای ضربان قلب بعدی، رهبر به دنبالهروها اطلاع میدهد که این ورودی متعهد شده است. دنبالهروها نیز پس از دریافت این اطلاع، دستور را بر روی ماشین حالت خود اعمال میکنند. در نهایت، رهبر نتیجه را به کلاینت بازمیگرداند.
این فرآیند تضمین میکند که یک دستور تنها زمانی اجرا میشود که به طور ایمن در اکثر سرورها کپی شده باشد و حتی اگر رهبر از کار بیفتد، این دستور از بین نخواهد رفت.
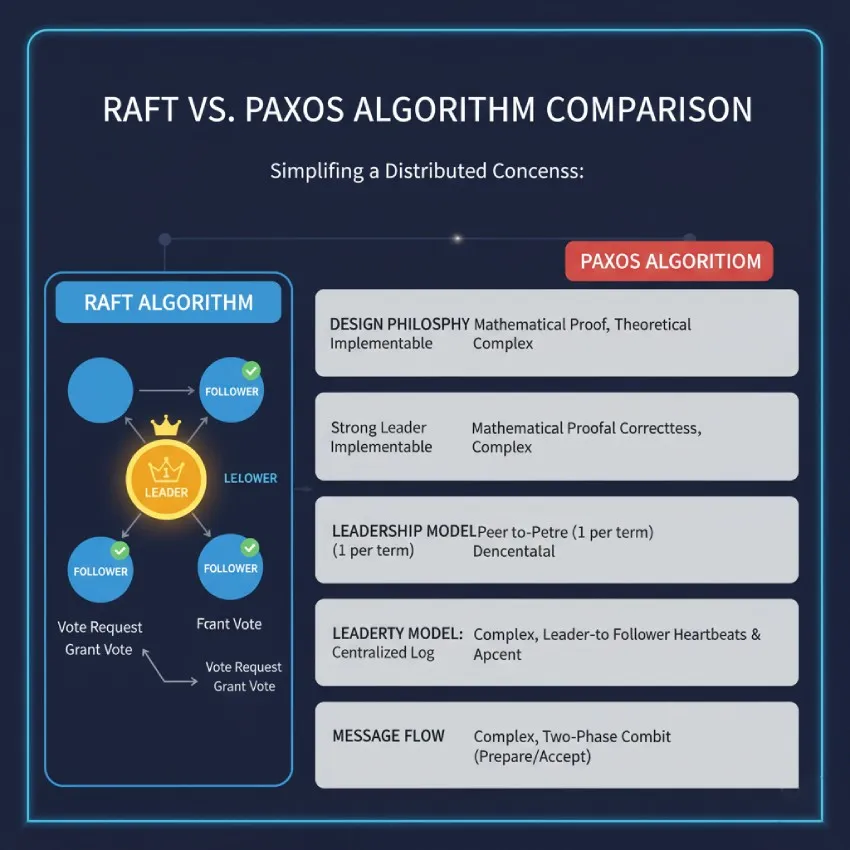
مقایسه الگوریتم رافت و الگوریتم پکسوس (Paxos)
یکی از دلایل اصلی توسعه رافت، پیچیدگی الگوریتم Paxos بود. در حالی که هر دو الگوریتم یک هدف را دنبال میکنند، رویکردهای متفاوتی دارند. جدول زیر تفاوتهای کلیدی این دو را نشان میدهد:
| ویژگی | الگوریتم رافت (Raft) | الگوریتم پکسوس (Paxos) |
| فلسفه طراحی | تاکید بر سادگی و قابل فهم بودن | تاکید بر اثبات ریاضی و صحت نظری |
| مدل رهبری | رهبری قوی و متمرکز. در هر زمان فقط یک رهبر وجود دارد. | مدل همتا به همتا و غیرمتمرکز. چندین گره میتوانند همزمان نقش "پیشنهاد دهنده" را داشته باشند. |
| جریان پیامها | ساده و یکطرفه: از رهبر به دنبالهروها. | پیچیده و دو فازی (Prepare/Promise و Propose/Accept). |
| قابل فهم بودن | بسیار بالا. طراحی شده برای آموزش و پیادهسازی آسان. | بسیار پایین. درک آن حتی برای متخصصان نیز دشوار است. |
| پیادهسازی | نسبتاً سادهتر. زیرمسائل به وضوح از هم جدا شدهاند. | بسیار پیچیده و مستعد خطا. |
| کاربرد عملی | بسیار گسترده در ابزارهای مدرن (etcd, Consul). | بیشتر در سیستمهای قدیمیتر (مانند Chubby گوگل) و به عنوان یک مفهوم تئوریک. |
به طور خلاصه، رافت یک رویکرد مهندسی برای حل مشکل اجماع است، در حالی که پکسوس یک رویکرد ریاضیاتی است. سادگی رافت باعث شده است که جامعه توسعهدهندگان آن را به طور گستردهتری بپذیرند.
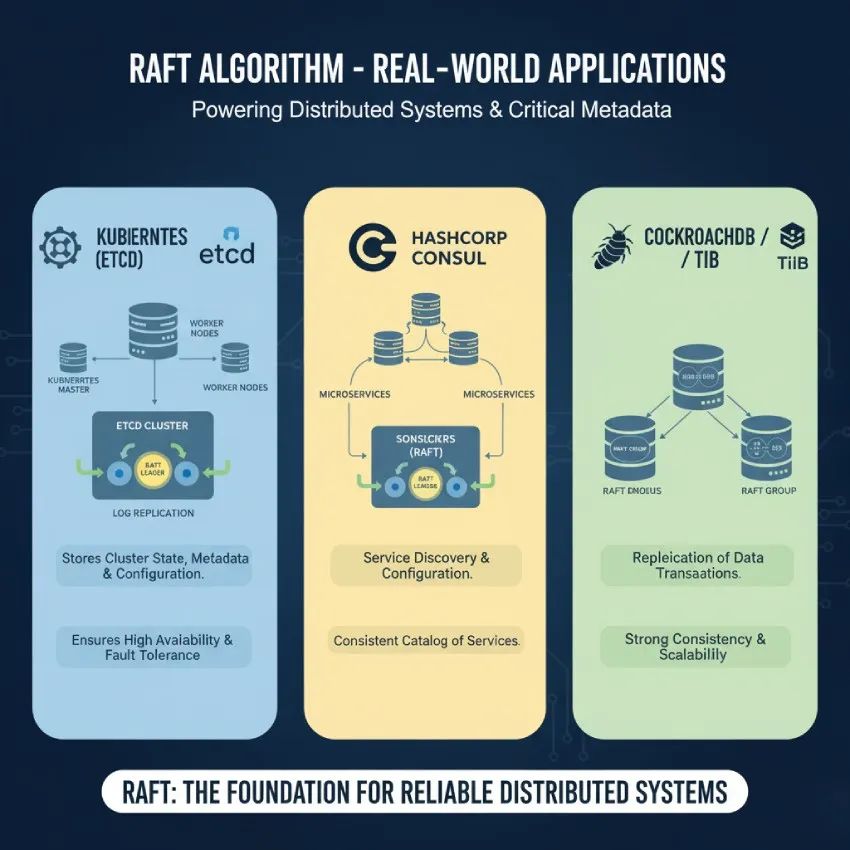
کاربردهای عملی الگوریتم رافت در دنیای واقعی
سادگی و قابلیت اطمینان رافت باعث شده است که در طیف وسیعی از سیستمهای توزیعشده مدرن به کار گرفته شود. در این سیستمها، رافت معمولاً برای مدیریت و همانندسازی فرادادههای حیاتی (Critical Metadata) استفاده میشود.
-
Kubernetes (با etcd): محبوبترین پلتفرم ارکستراسیون کانتینر، از etcd به عنوان پایگاه داده اصلی خود برای ذخیره تمام وضعیت خوشه (مانند اینکه کدام پاد روی کدام گره در حال اجراست) استفاده میکند. etcd خود از الگوریتم رافت برای همانندسازی این دادهها در چندین گره و تضمین تحملپذیری خطا بهره میبرد. اگر سرور اصلی Kubernetes از کار بیفتد، به لطف رافت، سرور دیگری به سرعت جایگزین شده و وضعیت خوشه حفظ میشود.
-
HashiCorp Consul: یک ابزار محبوب برای کشف سرویس (Service Discovery) و پیکربندی در معماریهای میکروسرویس است. Consul از رافت برای نگهداری یک کاتالوگ سازگار از تمام سرویسهای موجود و وضعیت سلامت آنها استفاده میکند.
-
CockroachDB: یک پایگاه داده توزیعشده SQL است که برای سازگاری و مقیاسپذیری بالا طراحی شده است. این پایگاه داده از رافت برای همانندسازی دادهها در بین گرههای مختلف استفاده میکند و تضمین میکند که تراکنشها به صورت اتمی و سازگار انجام شوند.
-
TiDB: یکی دیگر از پایگاههای داده توزیعشده SQL که از رافت برای همانندسازی دادهها بین اجزای ذخیرهسازی خود (TiKV) بهره میبرد.
اینها تنها چند نمونه از کاربردهای گسترده رافت هستند که نشاندهنده موفقیت این الگوریتم در حل یک مشکل پیچیده به روشی ساده و کارآمد است.
نتیجهگیری: چرا رافت برنده شد؟
الگوریتم اجماع رافت یک نمونه درخشان از این است که چگونه تمرکز بر سادگی و قابل فهم بودن میتواند منجر به تولید یک فناوری قدرتمند و پرکاربرد شود. در حالی که الگوریتمهایی مانند Paxos از نظر تئوری کامل بودند، پیچیدگی آنها مانع از پذیرش گسترده و پیادهسازی صحیح میشد. رافت با تقسیم مسئله اجماع به بخشهای قابل مدیریت (انتخاب رهبر، همانندسازی لاگ و ایمنی) و تعریف واضح نقشها، این مانع را از سر راه برداشت.
امروزه، رافت به عنوان ستون فقرات بسیاری از سیستمهای توزیعشدهای عمل میکند که ما هر روز با آنها سروکار داریم. درک اصول کارکرد آن نه تنها برای مهندسان نرمافزار که با این سیستمها کار میکنند ضروری است، بلکه دیدگاه ارزشمندی در مورد چالشهای ذاتی محاسبات توزیعشده و راهحلهای هوشمندانه برای غلبه بر آنها ارائه میدهد.
سوالات متداول در مورد الگوریتم رافت (FAQ)
آیا رافت برای بلاکچینها مناسب است؟
اگرچه رافت یک الگوریتم اجماع است، اما برای بلاکچینهای عمومی و بدون نیاز به مجوز (Public/Permissionless) مانند بیتکوین یا اتریوم مناسب نیست. دلیل اصلی این است که رافت بر اساس یک مجموعه ثابت و شناختهشده از گرهها کار میکند و به یک رهبر متمرکز در هر دوره متکی است. این مدل برای شبکههای خصوصی یا دارای مجوز (Private/Permissioned) که در آن اعضا قابل اعتماد هستند و تعدادشان مشخص است (مانند زنجیرههای تأمین یا سیستمهای مالی بین بانکی) بسیار کارآمد است، اما با ماهیت غیرمتمرکز و بیاعتماد بلاکچینهای عمومی در تضاد است.
بزرگترین محدودیت الگوریتم رافت چیست؟
بزرگترین محدودیت رافت، عملکرد آن است. از آنجایی که تمام ترافیک نوشتن باید از طریق یک رهبر واحد عبور کند، رهبر میتواند به یک گلوگاه (Bottleneck) تبدیل شود. در سیستمهایی با حجم نوشتن بسیار بالا، این مدل متمرکز ممکن است مقیاسپذیری را محدود کند. با این حال، برای اکثر کاربردها که وظیفه رافت مدیریت فرادادههای پیکربندی است و نه دادههای اصلی برنامه، عملکرد آن کاملاً کافی است.
اگر اکثریت گرهها به طور همزمان از کار بیفتند چه اتفاقی میافتد؟
رافت برای تحمل از کار افتادن اقلیت گرهها طراحی شده است. یک خوشه رافت با 2F + 1 گره میتواند از کار افتادن F گره را تحمل کند. برای مثال، یک خوشه ۵ گرهای میتواند خرابی ۲ گره را تحمل کند. اگر اکثریت گرهها (مثلاً ۳ گره در یک خوشه ۵ گرهای) از کار بیفتند، خوشه در دسترس نخواهد بود (Unavailable). این خوشه دیگر نمیتواند به اجماع برسد و بنابراین نمیتواند هیچ درخواست نوشتن جدیدی را پردازش کند. این یک رفتار طراحی شده برای حفظ سازگاری (Consistency) به قیمت در دسترس بودن (Availability) است (طبق قضیه CAP).
تفاوت بین Committed و Applied در رافت چیست؟
این یک تمایز مهم است. یک ورودی در لاگ زمانی "متعهد" (Committed) میشود که به طور ایمن در اکثر گرهها کپی شده باشد. در این مرحله، ما مطمئن هستیم که این ورودی هرگز از بین نخواهد رفت. اما یک ورودی زمانی "اعمال" (Applied) میشود که دستور آن بر روی ماشین حالت گره اجرا شود (مثلاً مقدار یک متغیر در حافظه تغییر کند). رافت تضمین میکند که ورودیها فقط پس از متعهد شدن، به ترتیب لاگ، اعمال میشوند. این جداسازی به بهینهسازی عملکرد کمک میکند.